

之前在明眸如初,看到了一篇文章,关于ai生成图片的。恰好比较感兴趣,于是就想着尝试一下。其实整体的安装步骤,已经这篇文章已经写的比较清楚了。可以照搬,一般问题不大。这里记录下我的安装方法。
由于系统的anaconda比较老旧,安装的python版本也不对应,导致通过conda创建的虚拟环境安装失败了,Stable Diffusion web UI推荐的python环境为3.10.6,所以直接下载了这个版本安装,下载地址:https://www.python.org/downloads/windows/,由于电脑上的python版本比较多,也不想把这个东西加到系统变量的path内,所以可以直接通过运行指定的python可执行文件创建venv。
F:\Pycharm_Projects\stable-diffusion-webui>D:\Python3.10.6\python.exe -m venv venv
F:\Pycharm_Projects\stable-diffusion-webui为Stable Diffusion web UI的下载目录。
创建虚拟环境之后,修改webui-user.bat指定python文件路径和venv的路径,如下:
@echo off set PYTHON=D:\Python3.10.6\python.exe set GIT= set VENV_DIR=F:\Pycharm_Projects\stable-diffusion-webui\venv set COMMANDLINE_ARGS= call webui.bat
执行bat文件的时候切换到代码目录下,否则会提示找不到webui.bat。
由于需要通过github下载各种库,所以执行webui-user.bat之前,最好设置好梯子。以免文件下载失败,导致安装失败。
由于我的电脑之前跑过yolov5,所以cuda的环境之前就已经安装好了,如果没有安装,通过这个地址下载安装https://developer.nvidia.com/cuda-11-7-0-download-archivetorch,一般网络通常的情况下环境直接通过bat自动就全部完成了,安装完成之后会在7860端口启动一个web服务:
F:\Pycharm_Projects\stable-diffusion-webui>webui-user.bat venv "F:\Pycharm_Projects\stable-diffusion-webui\venv\Scripts\Python.exe" Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)] Commit hash: 22bcc7be428c94e9408f589966c2040187245d81 Installing requirements for Web UI Launching Web UI with arguments: No module 'xformers'. Proceeding without it. Loading weights [6ce0161689] from F:\Pycharm_Projects\stable-diffusion-webui\models\Stable-diffusion\v1-5-pruned-emaonly.safetensors Creating model from config: F:\Pycharm_Projects\stable-diffusion-webui\configs\v1-inference.yaml LatentDiffusion: Running in eps-prediction mode DiffusionWrapper has 859.52 M params. Applying cross attention optimization (Doggettx). Textual inversion embeddings loaded(0): Model loaded in 3.0s (load weights from disk: 0.2s, create model: 0.4s, apply weights to model: 0.5s, apply half(): 0.6s, move model to device: 0.5s, load textual inversion embeddings: 0.8s). Running on local URL: http://127.0.0.1:7860
通过浏览器的7860端口就可以访问服务了:
相关的模型可以通过https://civitai.com这个网站下载

点击右侧的绿色箭头可以看到支持的环境:

选择支持Automatic 1111 Web UI (Local) 的模型即可,下载之后放入Stable Diffusion web UI目录下的models\Stable-diffusion文件夹下:

点击页面的刷新按钮,重新加载即可选择不同的模型进行生成。
最后需要关注的就是prompt 和negative prompt 关键词,这两个关键词除了描述要生成的对象,更多的一部分是对ai生成的图片的一些限制说明,例如分辨率,不要生成卡通图片之类的。这些可以自己去尝试,我尝试了两组,效果还算不错:
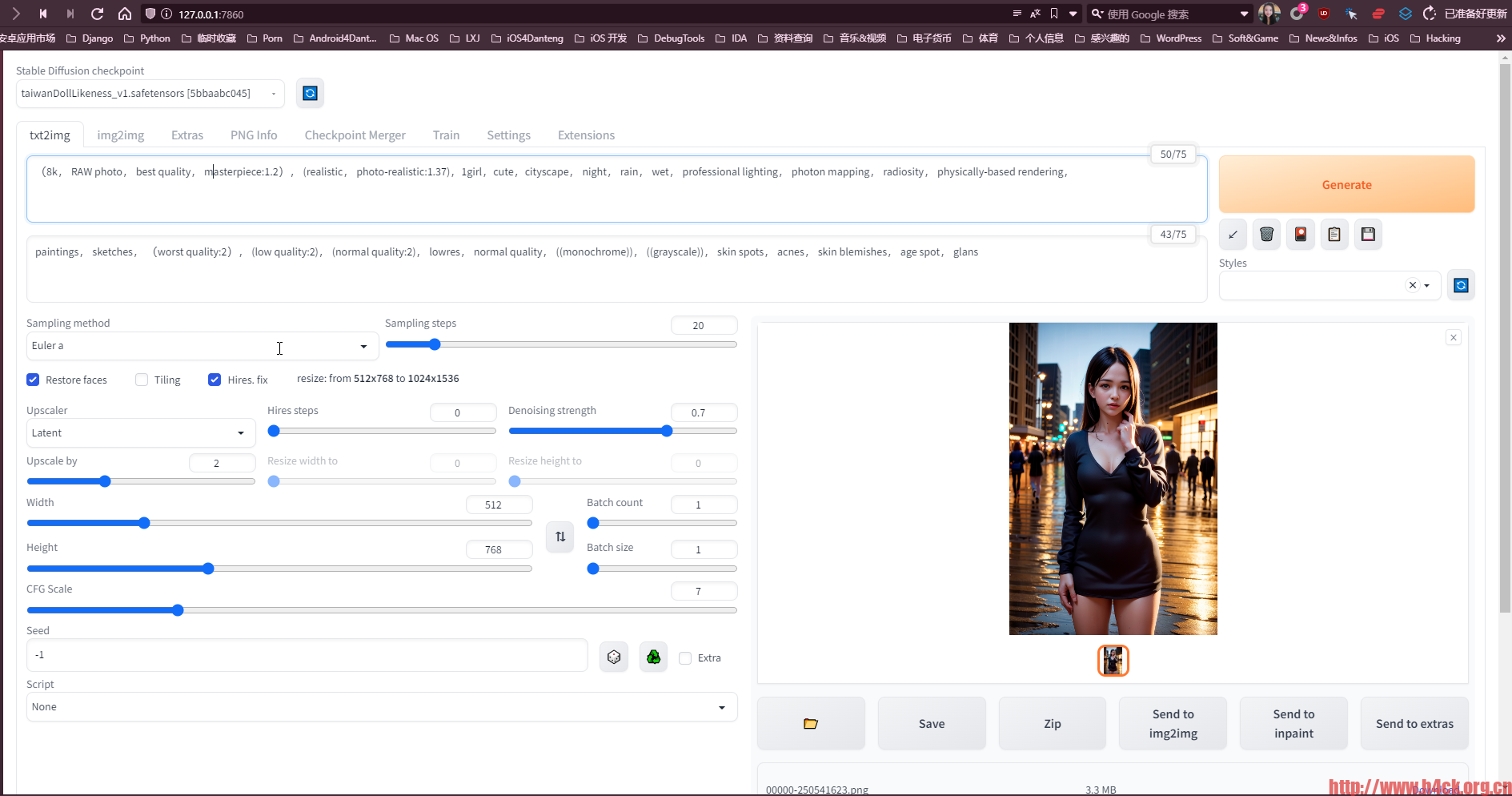
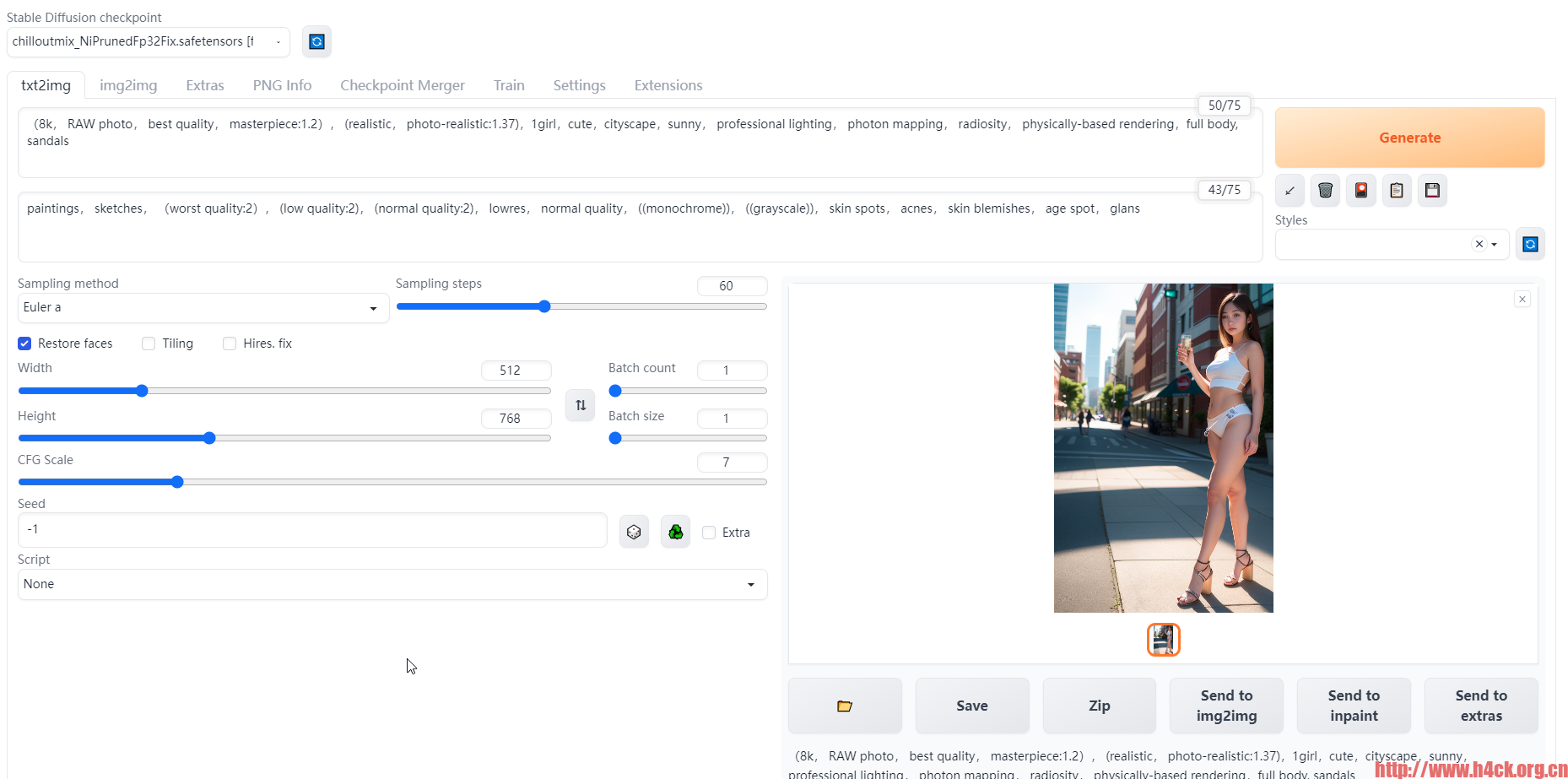
第一组: prompt: <lora:addielyn_v1_chilloutmix_NiPrunedFp16Fix_100_33pic_epoc:0.6666> extremely detailed ((addielyn)), detailed eyes, (Best quality details:1.2),realistic,8K High definition,(1girl:1.2),Ultra Detailed,High quality texture,intricate details,detailed texture,finely detailed,high detail,extremely detailed cg,High quality shadow,Detailed beautiful delicate face,Detailed beautiful delicate eyes,Depth of field,Ray tracing,(a beautiful25age years old sexy korean woman:1.1),medium breast, tall_female, beautiful_legs, Glow Eyes,blush, perfect body,skinny, (black sweater:1.4), (open grey coat:1),(short plaid tight skirt :1.2), (stockings_garterbelt:1.1, stilleto:1.1), (bob cut:1.1), street, sunlight, kneeling on sofa, earrings,necklace, model, looking at viewer, from side, dynamic pose, mole under eye, Negative prompt: (worst quality, low quality:1.4),lowres,low quality anatomy,ugly,more than two people,split picture,split screen,two or more pictures,Ignoring prompts,individual screen,low quality four fingers and low quality thumb,complicated fingers,fingerless,extra limbs,signature,watermark,username,fat,Chubby,dark skin,ugly face,ugly nose,outline,low quality face,low quality eyes,polydactyly,low quality body,low quality ratio,broad shoulders,low detail clothes,cheekbone, animal, dolphin, latex, nsfw, posing, hands, 第二组: prompt: (8k, RAW photo, best quality, masterpiece:1.2), (realistic, photo-realistic:1.37),1girl,cute,cityscape, night, rain, wet, professional lighting, photon mapping, radiosity, physically-based rendering, (8k, RAW photo, best quality, masterpiece:1.2), (realistic, photo-realistic:1.37),1girl,cute,cityscape,sunny , professional lighting, photon mapping, radiosity, physically-based rendering,full body Negative prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans
可以切换不同的模型进行尝试:



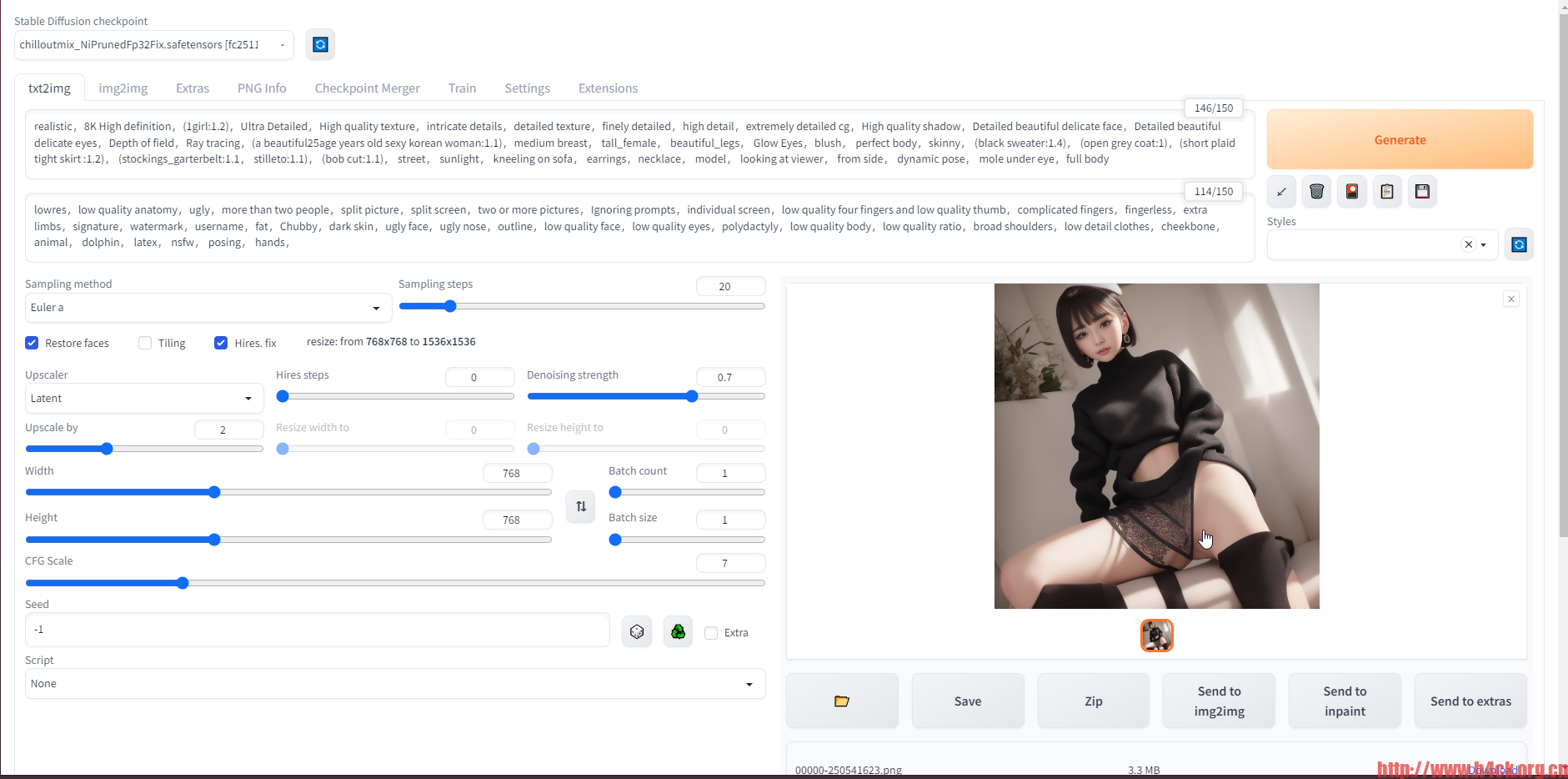
对于我的电脑来说768*768基本就是极限了,显存基本跑慢了,如果到1024直接就崩溃了提示内存不足:
github上也给出了具体的解决方案:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Troubleshooting,我还没尝试,等后续有时间再尝试。
生成的图片,效果也还ok:






prompt可以通过https://replicate.com/methexis-inc/img2prompt 这个网站上传图片生成prompt

生成的prompt:
a woman sitting on top of a chair next to a desk, a character portrait by Zhang Han, pixiv, dau-al-set, full body, lovely, elegant
测试效果:


chatgpt生成的效果一般,可能是我问的方法不对~~
个人感觉,主要应该是分词数量不够。
参考链接:
https://zhuanlan.zhihu.com/p/612676189
https://www.chinaz.com/2023/0328/1510281.shtml
https://github.com/AUTOMATIC1111/stable-diffusion-webui
18 comments
hires.fix和restore faces取消勾选可以大幅度降低显存占用 2080 8G都能直接跑1920*1080的图
B站“秋葉aaaki”有出图和训练的视频教程
tags.novelai.dev 这是标签超市 里面有标签的效果图可以预览
script可以出各种标签组合的效果图 初期找标签很有用
标签可以用(XXX:1.2)这种格式来修改数字加强在图中占比
开始可以生成小分辨率图节省时间 找到满意的图后用图生图加大分辨率
分辨率对实际效果影响非常大 大分辨率经常图中会有多人出现
这个网站不错·~
restore faces我在测试的时候最好还是勾选,同样的参数,勾选和不勾选差别太大了,如果不勾选脸部基本没法看。效果对比:




不勾选:
勾选优化:
参数:
prompt:
(8k, RAW photo, best quality, masterpiece:1.2), (realistic, photo-realistic:1.37),1girl,cute,cityscape,sunny, professional lighting, photon mapping, radiosity, physically-based rendering,full body, sandals
negative prompt:
paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans
模型:chilloutmix
脸异常是标签的原因
标点符号最好用小写的
试一些其他的标签(可能两个好的词碰一起反而会出不好的图)
civitai.com里的图可以看他们用的什么标签
可以试下这组标签 和你一样的模型 一般不会出有问题的图
girl,(detailed facial features),pale skin, seductive look, HDR,cinematic lighting, reflections,narrow waist,dress,soft focus,high detailed skin,photorealistic,eyelashes,blush
paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot,animated, cartoon, ((blurry)), ((duplicate body parts)),(disfigured), (poorly drawn), (extra limbs), mutated, bad art, gross, ugly, poor quality, low quality,logo, watermark, text
采样方法(Sampler):Euler a(推荐另一个“DPM++ SDE Karras”感觉某些情况下阴影更真实一些 出图速度和Euler a也都是第一梯队的)
采样迭代步数(Steps):30
提示词相关性(CFG Scale):10
标签肯定是英文分割的,这个是常识啊。civitai.com里面贴的图,通过他们的代码用同样的模型,生成的效果也一般,应该还是参数或者标签问题。

用你的参数,脸部感觉还有有些异常:
按照你头像来的吗
当然不是哈,嘿嘿,不过那些图片生成的你这么一说还真的有点像。
主要是香港,台湾和韩国的模型多少都有点相似。
这么吃显存吗?我这AMD显卡跑不了!
应该也能跑,github那个链接有优化方案。
我去试试!
没有灵气
其实这个嘛 模型就能说明一些问题了,doll,嘿嘿。
这个我也正在玩,挺好玩的。tag有一个插件可以自动转换的,在里在打中文就自动转成正确的关键字。
还有这种东西,不错。感觉你生成的比我生成的更真一些,还是我的错觉?
这个要慢慢微调,或者直接用别人的Lora来生成。我现在在自己训练,生成的照片也不太好,不过越来越好是真的。
我倒是有足够多的图,不过还没开始自己训练
我发现相同的代码,生成的图片也不都完全一样!
不要随机seed生成的就会差不多了 嘻嘻