'''
--------------------------------------------------------------------------------
福利数据解析
基础数据分析,标题分词,词频统计
-----------------------------------
by:obaby
email: root@obaby.org.cn
blog:http://www.h4ck.org.cn
===================================
参考链接:https://sparkbyexamples.com/pyspark/select-columns-from-pyspark-dataframe/
-------------------------------------------------------------------------------
'''
import jieba
# 通过spark read csv格式文件,从csv header解析数据结构
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie.csv")
# 数据格式
csv.printSchema()
root
|-- id: string (nullable = true)
|-- create: string (nullable = true)
|-- update: string (nullable = true)
|-- name: string (nullable = true)
|-- describe: string (nullable = true)
|-- source_id: string (nullable = true)
|-- publish_time: string (nullable = true)
|-- play_count: string (nullable = true)
|-- good_count: string (nullable = true)
|-- bad_count: string (nullable = true)
|-- link_count: string (nullable = true)
|-- comment_count: string (nullable = true)
|-- designation: string (nullable = true)
|-- category_id: string (nullable = true)
|-- porn_site_id: string (nullable = true)
|-- uploader_id: string (nullable = true)
|-- producer: string (nullable = true)
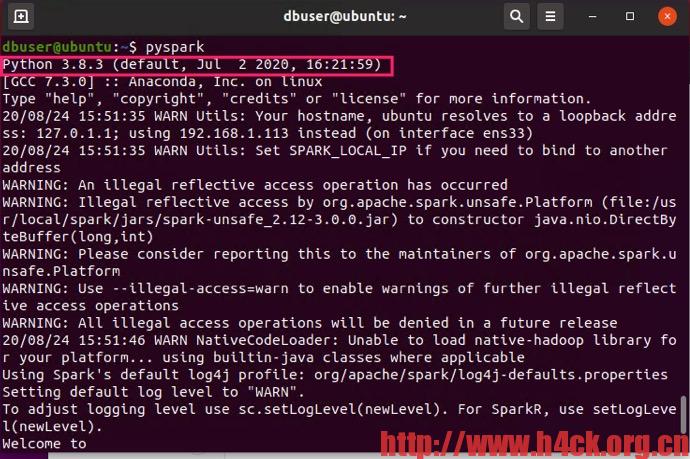
Porn Data Anaylize — Spark安装
spark默认使用的Python版本为2,可以修改.bashrc文件让spark默认使用python3。修改.bashrc增加如下行:
# anaconda
export ANACONDA_HOME=/home/dbuser/anaconda3/
export PATH=$ANACONDA_HOME:$PATH
# spark
export PYSPARK_PYTHON=/home/dbuser/anaconda3/bin/python3
然后重新启动pyspark就是3了,anaconda下的python文件版本也是2。
Porn Data Anaylize — Hadoop安装
这是一个系列的数据分析相关项目,包括环境搭建,数据分析,分析代码,分析报告等。目前数据来源于爬取到的100,000+数据
文章主要介绍相关的方法和原理,也算是自己对于大数据的一个初步的认识。
代码不会涉及具体的数据信息。如果需要相关的数据,可以参考以下文章自己爬取相关的数据信息:
安装参考的是《Python + Spark 2.0+Hadoop机器学习与大数据实战》(林大贵 著),首先吐槽一下,林大贵的几本书前几章的内容完全一样,尤其是上面提到的这本与《Hadoop + Spark大数据巨量分析与机器学习实战》,两本书前7章内容完全一致。
买了两本书其实相当于买了一本半,并且重复的都是非常基础的部分。对于整本书来说倒是降低了写作的难度和时间,并且两本书的实例也基本一致,不过使用的语言略有不同。
书上介绍的安装版本比较老旧,也没有必要去安装一个老旧的版本。所以这里我安装的是3.3.0 具体的安装流程可以参考这个链接:http://hadoopspark.blogspot.com/2015/09/4-hadoop-26-single-node-cluster.html
不过需要注意的是里面的几条命令可能稍微有些问题: 使用下面的这条命令生成的key文件对应的host是本机的主机名:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
如果系统没有设置hostname,可以使用下面的命令生成key:
ssh localhost ssh-keygen -t rsa
两者的区别在于第一条命令生成的是username@hostname,第二条名称生成的是username@localhost
攻城略地 再下一Porn
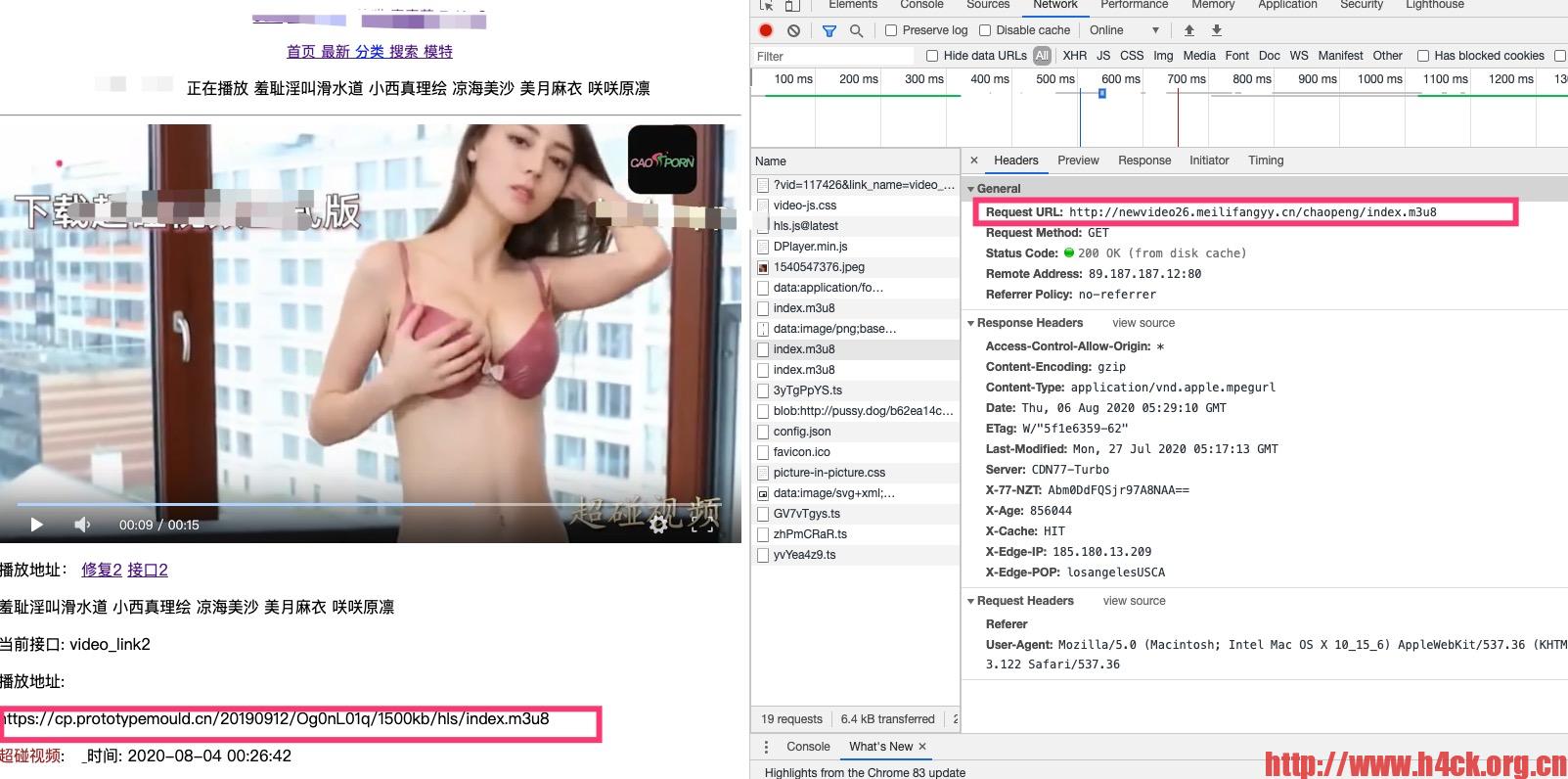
查看爬取的数据的时候,突然发现一个网站的视频不能播放了,所有的视频在播放的时候都会显示下载正式版。

这尼玛当时就尴尬了,访问播放地址就会发现,重定向到另外一个域名了。
上一篇文章的代码(开源Github)
基于ffmpeg的m3u8下载[调整key替换逻辑,更新解析逻辑]

闲来没事,找了个av网站,看了几个视频,然后想下载一下。结果发现多年不上这些av网站,现在的av网站播放的源文件已经不是avi或者mp4了,而是m3u8的播放列表。在firefox中可以使用Video DownloadHelper 来获取相应的下载地址,但是有的时候如果m3u8中包含的是播放列表,会无法获取下载链接。
于是就想着怎么直接下载文件,其实通过ffmpeg可以很方便的获取下载链接:
只需要下面的一样命令:
ffmpeg -protocol_whitelist "file,http,crypto,tcp,https,tls" -i https://videox11.ynkcq.com:8081/20200109/8Pr79HKk/600kb/hls/index.m3u8 -c copy out.mp4