
说是pdf 印章识别,其实准确来说是图片印章识别。当然,这个功能还是要继续前面的话题。流程自动化,简言之就是需要在用户上传完盖章之后的所有文档图片之后将图片拼接为 pdf,并且,还要检测上传的图片是否已经盖章。之所以要自动检测是因为:看了下现在用户上传的图片,有很多并没盖章,企图蒙混过关。虽然后续还有审核功能,但是与其增加审核的工作量,不如直接在源头就卡死,如果没有盖章禁止结束流程。
黑客程序媛 / 逆向工程师 / 人工智能学徒 / 用爱发电的独立开发者
说是pdf 印章识别,其实准确来说是图片印章识别。当然,这个功能还是要继续前面的话题。流程自动化,简言之就是需要在用户上传完盖章之后的所有文档图片之后将图片拼接为 pdf,并且,还要检测上传的图片是否已经盖章。之所以要自动检测是因为:看了下现在用户上传的图片,有很多并没盖章,企图蒙混过关。虽然后续还有审核功能,但是与其增加审核的工作量,不如直接在源头就卡死,如果没有盖章禁止结束流程。
代码原地址: https://github.com/nihui/ncnn-android-yolov5
我在这里只是替换了模型信息,其余的内容基本没有修改。
原工程并没有写如何进行模型转换,模型转换可以参考这篇文章:https://blog.csdn.net/flyfish1986/article/details/116604907里面写的比较详细了。
这里简单的做个备份,不想跳转的可以直接参考下面的内容:
- 导出onnx
bash
python models/export.py --weights yolov5s.pt --img 320 --batch 1- onnx-simplifer简化模型
bash
python -m onnxsim yolov5s.onnx yolov5s-sim.onnx- 专函为ncnn
bash
./onnx2ncnn yolov5s-sim.onnx yolov5s.param yolov5s.bin- 处理转ncnn产生的Unsupported slice step !
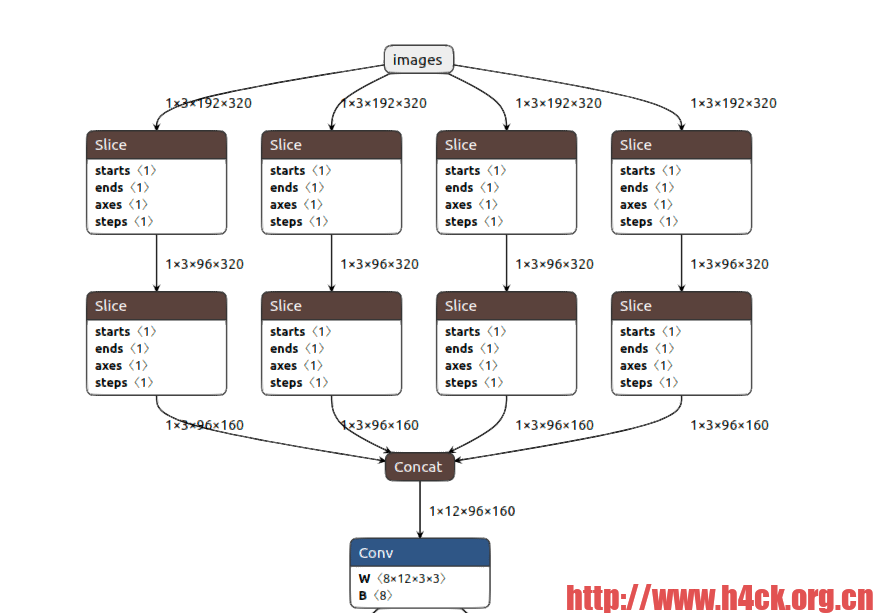
1).处理YOLOv5的Focus模块,将多个slice节点转换为一个focus节点


首页 设置页面
在之前的文章《Yolov5 Android tf-lite方式集成》中,导出tf-lite方式的模型使用的是https://github.com/zldrobit/yolov5.git中的tf.py。晚上尝试用yolov5 最新版本的代码的export.py导出,如果不想修改命令行参数,可以字节修改以下代码:
# 需要修改参数 data weights batch-size
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'data/ads.yaml', help='dataset.yaml path')
parser.add_argument('--weights', type=str, default=ROOT / 'best.pt', help='weights path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--optimize',default=True, action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=13, help='ONNX: opset version')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
parser.add_argument('--include', nargs='+',
default=['torchscript', 'onnx'],
help='available formats are (torchscript, onnx, coreml, saved_model, pb, tflite, tfjs)')
opt = parser.parse_args()
print_args(FILE.stem, opt)
return opt




上一篇文章中提到的torchscript方式在手机上实际的检测效果差了很多,于是尝试了另外两种方式,第二种方式目前还有问题,所以就先不写了。这篇文章介绍的是第三种方法。zldrobit创建了一个ftlite的分支,https://github.com/zldrobit/yolov5.git。要使用这个方法文章中步骤也写的比较详细了。
1.克隆相关的分支:
git clone https://github.com/zldrobit/yolov5.git cd yolov5 git checkout tf-android