IDA对Unicode的处理不能说很烂,但是有的时候却比较蛋疼。例如神马中文之类的,但是除此之外,对于英文的字符串处理在部分地方也是有问题的,例如上面的内容。
同样在idb刚创建的时候对于unicode字符串的解析也存在问题,例如下面的内容:

真正的字符串内容应该是ReadFromRegistry。但是ida很蛋疼的把第一个R当作dw给处理掉了,于是剩下了一个眉头的身子。
在创建string之后默认是采用的当前idb数据库的字符串格式,如果想要创建正确的字符串需要用到SetAsciiStyle(http://www.hex-rays.com/products/ida/support/idadoc/613.shtml)。

需要将新创建的字符串设置为Unicode,如果有多个字符串需要创建那么最简单的办法就是将默认字符串类型修改为Unicode,这样新创建的字符串就能正常的识别了,如果不想修改这个东西可以使用下面的代码:
//
// This idc adds shortcuts to create unicode strings.
//
#include
static main()
{
DelHotkey("Shift+U");
AddHotkey("Shift+U","createunicodestring");
Message("Press Shift+U @ EA to create unicode string");
Message("Registered idc functions");
}
// http://www.hex-rays.com/products/ida/support/freefiles/ldrmodules.idc
static MakeNameWithType(ea, type)
{
auto old_type;
old_type = GetLongPrm(INF_STRTYPE);
SetLongPrm(INF_STRTYPE, type);
MakeStr(ea, BADADDR);
SetLongPrm(INF_STRTYPE, old_type);
}
static createunicodestring()
{
auto ea;
ea= ScreenEA();
MakeNameWithType(ea,ASCSTR_UNICODE);
}
修改完成之后的数据应该是这个样子的:
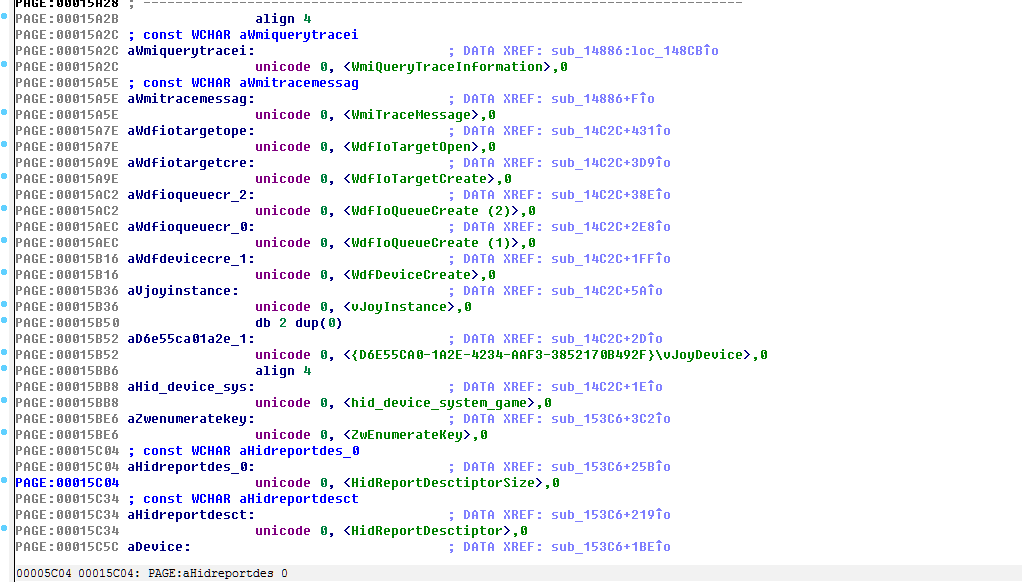
但是这个脚本没有办法处理中文字符,同样用ida自带的创建字符串窗口也没有办法处理中文。为了更方便一些可以使用下面的插件,快捷键Shift+U,会自动将当前数据创建为Unicode格式的字符串。
相关 链接:
http://hiddencodes.wordpress.com/2012/02/09/idc-script-create-unicode-string/
http://www.hex-rays.com/products/ida/support/idadoc/613.shtml
http://www.hex-rays.com/products/ida/support/idadoc/1433.shtml
http://tuts4you.com/download.php?view.3415
http://www.h4ck.org.cn/2012/04/ida-unicode-string-anylist-and-comment-maker/