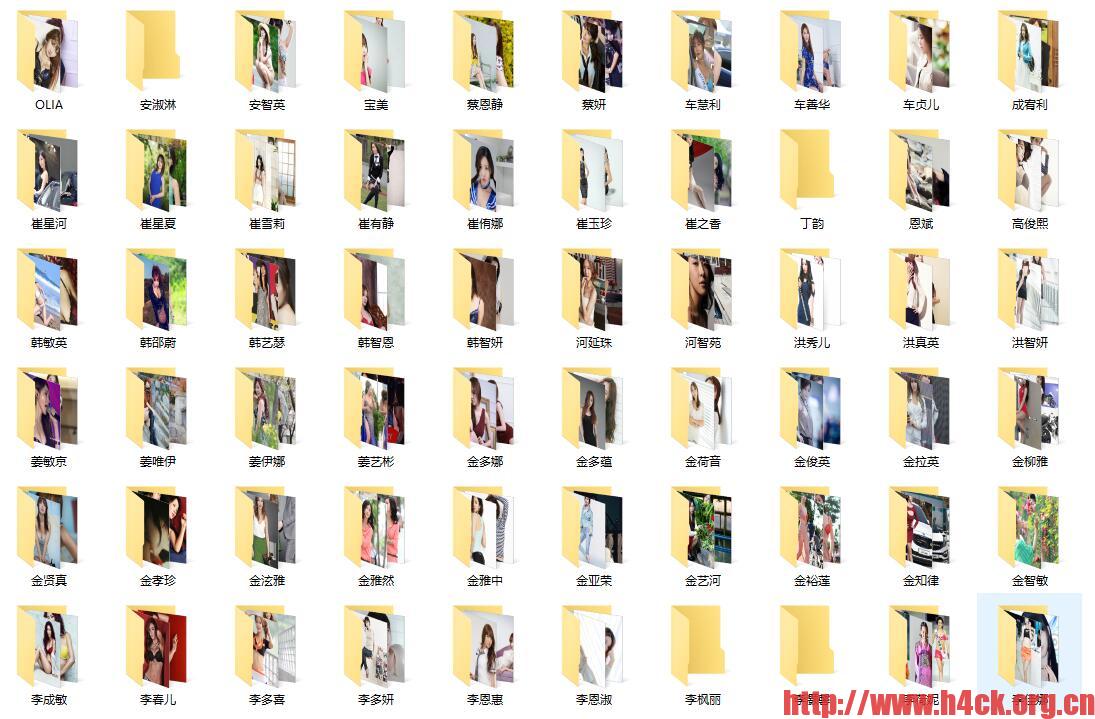
对于美女的热爱无法自拔 😆 ,经常会去搜索一些美女图片,下载下来,然后找时间慢慢欣赏。主要用途是用作电脑桌面手机桌面,通常会百度或者bing去搜索下找到图片下载。相对来说能够直接用作桌面的图片并不多,多数是尺寸问题,并不是十分合适。但是即使不能直接用,可以用ps修改下图片尺寸,或者欣赏也是好的啊。 🙂
以前曾经从一个网站mzitu.com 爬了一些图片,但是最近访问的时候却发现网站挂了~~

最近在搜索图片的时候又发现了一个http://www.a6d.cn 各种图片也不少,于是就产生了全站备份的想法。好处是这两个网站都没有反爬虫机制,可以直接进行处理。为了不过度增加服务器负担就没有用多线程。
相对来说爬取数据也比较简单,整体可以分为4步:
- 获取所有的美女姓名和链接

- 获取单个美女的所有页面地址 底部链接
- 针对单个美女的单个页面进行枚举,获取所有的文章页面链接 左侧列表页面的链接
- 对文章页的图片进行遍历下载

到这里所有的操作就完成了,剩下的就可以交给时间了。
代码:
# -*- coding:utf-8 -*-
import os
import requests
from bs4 import BeautifulSoup
HEADERS = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Referer': 'http://www.a6d.cn/'
}
DIR_PATH = "H:/图片/a6d.cn"
def get_url_source_code(url):
souce = requests.get(url=url, headers=HEADERS, timeout=10)
html = souce.content
html_doc = str(html, 'utf-8')
return html_doc
def save_pic(url, path):
try:
img = requests.get(url, headers=HEADERS, timeout=10).content
img_name = os.path.join(path, str(url).split('/')[-1])
print('[S] 下载图片:' + img_name)
with open(img_name, 'ab') as f:
f.write(img)
print('[S] 下载图片成功')
except Exception as e:
# print(e)
print('[S] 下载图片失败: ' + str(e))
def mark_dir(flot_name):
"""
检测文件夹是否创建,没有创建则创建文件夹,创建了就跳过
"""
print('[C] 创建目录: ' + flot_name)
PATH = os.path.join(DIR_PATH, flot_name)
if not os.path.exists(PATH): # 检测是否有这个文件夹
os.makedirs(PATH)
os.chdir(PATH)
return PATH
def get_all_models():
print('-' * 70)
print('[A] 分析所有美女姓名 链接信息......')
html_doc = get_url_source_code('http://www.a6d.cn/mnzt/hongjiyeon/index.htm')
# print(html)
bs = BeautifulSoup(html_doc, "html.parser").find('div', class_='zhuti')
# print(bs)
zzr = bs.find_all('a')
ll = []
for z in zzr:
url = 'http://www.a6d.cn' + z.get("href")
i = {
'url': url,
'name': z.get_text()
}
print('[*] 名字: ' + z.get_text() + ' URL:' + url)
ll.append(i)
print('[A] 美女总数: ' + str(len(ll)) + ' 全部解析完成')
print('-' * 70)
return ll
def get_sub_pages(url):
print('_' * 70)
print('[A] 分析子页面地址......')
print('[A] ' + url)
html_doc = get_url_source_code(url)
bs = BeautifulSoup(html_doc, "html.parser").find('span', class_='pagecss')
# print(bs)
if bs is None:
return [url]
urls = []
surls = bs.find_all('a')
for u in surls:
link = 'http://www.a6d.cn' + u.get("href")
if link not in urls:
urls.append(link)
# print(link)
print('[A] 子页面分析完成,一共 ' + str(len(urls)) + ' 页')
print('_' * 70)
return urls
def get_artical_page_links(url):
print('_' * 70)
print('[A] 解析最终页面地址......')
html_doc = get_url_source_code(url)
bs = BeautifulSoup(html_doc, "html.parser").find('div', class_='pic_article mtop10')
surls = bs.find_all('a')
urls = []
for u in surls:
link = 'http://www.a6d.cn' + u.get("href")
if link not in urls:
urls.append(link)
# print(link)
print('[A] 最终面分析完成,一共 ' + str(len(urls)) + ' 页')
print('_' * 70)
return urls
def get_all_image_links(url, name):
print('_' * 70)
print('[A] 解析图片地址......')
html_doc = get_url_source_code(url)
bs = BeautifulSoup(html_doc, "html.parser").find('div', id='articleContnet')
if bs is None:
bs = BeautifulSoup(html_doc, "html.parser").find('div', class_='pic_article mtop10')
# print(bs)
urls = []
surls = bs.find_all('img')
floder = mark_dir(name)
for u in surls:
link = 'http://www.a6d.cn' + u.get("src")
if link not in urls:
# print(link)
urls.append(link)
save_pic(link, floder)
print('_' * 70)
print('[A] 图片下载完成,当前页面图片一共 ' + str(len(urls)) + ' 张')
if __name__ == '__main__':
print('*' * 80)
print('韩国美女 图片下载器')
print('http://www.a6d.cn')
print('by: obaby')
print('http://www.obaby.org.cn')
print('http://www.h4ck.org.cn')
print('*' * 80)
ll = get_all_models()
errors = []
for l in ll:
page_url = l['url']
name = l['name']
try:
# 解析当前模特色所有的子页面
pgs = get_sub_pages(page_url)
for p in pgs:
# 从子页面解析所有的文章列表
apgs = get_artical_page_links(p)
for a in apgs:
# 从所有的文章中解析图片链接冰进行下载
get_all_image_links(a, name)
except:
print('[E] 解析失败')
errors.append(page_url)
print('[D] 全部下载完成。')
print('[D] 下载失败数量:' + str(len(errors)))
if len(errors) > 0:
log_string = '\r\n'.join(errors)
with open('error_log', 'w', encoding="utf-8") as f:
f.write(log_string)
print('*' * 80)
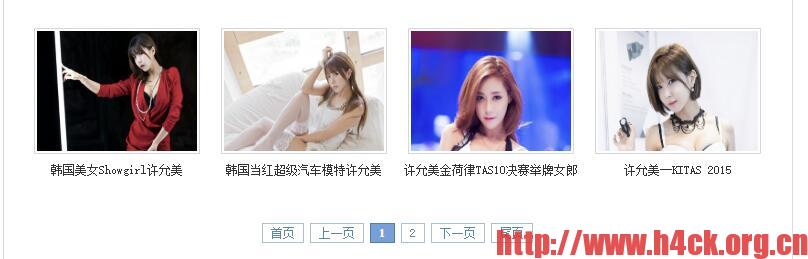
除此之外,并没有把网站的数据全部爬取下来,仔细观察就会发现右侧有个导航栏

而有的文章只在这个分类目录下能找到,从上面的美女列表却找不到相关文章。于是如果要爬取所有的数据还要遍历导航栏内的文章。
相关代码:
def get_all_categories():
print('-' * 70)
print('[A] 分析所有分类页面信息......')
html_doc = get_url_source_code('http://www.a6d.cn/Article/hgmfzb/index.html')
# print(html_doc)
bs = BeautifulSoup(html_doc, "html.parser").find('div', class_='sidebar')
# print(bs)
zzr = bs.find_all('a')
ll = []
for z in zzr:
url = 'http://www.a6d.cn' + z.get("href")
i = {
'url': url,
'name': z.get_text()
}
print('[*] 名字: ' + z.get_text() + ' URL:' + url)
ll.append(i)
print('[A] 分类总数: ' + str(len(ll)) + ' 全部解析完成')
print('-' * 70)
return ll
# 从分类下载 需要获取网页标题来创建目录
def get_all_image_links(url, name):
print('_' * 70)
print('[A] 解析图片地址......')
html_doc = get_url_source_code(url)
bs4 =BeautifulSoup(html_doc, "html.parser")
bs = bs4.find('div', id='articleContnet')
if bs is None:
bs = BeautifulSoup(html_doc, "html.parser").find('div', class_='pic_article mtop10')
# print(bs)
urls = []
surls = bs.find_all('img')
title = bs4.title.string
floder = mark_dir(title)
for u in surls:
link = 'http://www.a6d.cn' + u.get("src")
if link not in urls:
# print(link)
urls.append(link)
save_pic(link, floder)
print('_' * 70)
print('[A] 图片下载完成,当前页面图片一共 ' + str(len(urls)) + ' 张')
if __name__ == '__main__':
print('*' * 80)
print('韩国美女 图片下载器')
print('http://www.a6d.cn')
print('by: obaby')
print('http://www.obaby.org.cn')
print('http://www.h4ck.org.cn')
print('*' * 80)
ll = get_all_categories()
errors = []
for l in ll:
page_url = l['url']
name = l['name']
try:
# 解析当前模特色所有的子页面
pgs = get_sub_pages(page_url)
for p in pgs:
# 从子页面解析所有的文章列表
apgs = get_artical_page_links(p)
for a in apgs:
# 从所有的文章中解析图片链接冰进行下载
get_all_image_links(a, name)
except:
print('[E] 解析失败')
errors.append(page_url)
print('[D] 全部下载完成。')
print('[D] 下载失败数量:' + str(len(errors)))
if len(errors) > 0:
log_string = '\r\n'.join(errors)
with open('error_log', 'w', encoding="utf-8") as f:
f.write(log_string)
print('*' * 80)
最终效果: