之前写过一个mht文件的解析工具,不过当时解析的文件都是ie生成的。没有测试过chrome解析的文件。今天在github上看到一个反馈:https://github.com/obaby/mht-image-extractor/issues/1 qq浏览器保存的文件无法提取,chrome保存的文件会直接崩溃。下载附件的文件解析后发现,这两个文件的文件格式与ie的文件格式并不一致,文件头改成了如下的内容:
From:
Snapshot-Content-Location: https://mp.weixin.qq.com/s?__biz=MzU1NzQ3MTg5OQ==&mid=2247483652&idx=1&sn=a16979f8b088cb60fb63f210536d5288&chksm=fc3400f0cb4389e698a5a3ce1bf6a6ab3ff6f547bb4db409893850b0c502053d1fea40f70fda&sessionid=0&scene=126&subscene=0&clicktime=1599463540&enterid=1599463540&ascene=3&devicetype=android-28&version=27001237&nettype=ctnet&abtest_cookie=AAACAA%3D%3D&lang=zh_CN&exportkey=AUPVIV8Yt1hvPJ2dYKFWhvM%3D&pass_ticket=eTzcuEu%2BGavsf30E3HDErOhtb18ThPDhge008pIBzY7AFq0IuG1LUgojTpufwqUZ&wx_header=1
Subject: =?utf-8?Q?=E6=B1=89=E6=9C=8D=E4=B8=A8=E5=BD=BC=E5=B2=B8=E8=8A=B1=E5=BC=80?=
Date: Sun, 20 Sep 2020 00:50:44 -0000
MIME-Version: 1.0
Content-Type: multipart/related;
type="text/html";
boundary="----MultipartBoundary--Bx5ubV1DnfL8hvvsySfZL6MQeLa58tWkfwrQGpothO----"
而ie保存的文件头则是如下格式的:
Content-Type: multipart/related; start=op.mhtml.1267442701515.fe60c16c115c15f9@169.254.195.209; boundary=----------pMKI1vNl6U7UKeGzbfNTyN Content-Location: http://a.10xjw.com/feizhuliu/89905.html
Subject: =?utf-8?Q?=E8=B6=85=E7=BE=8E=E4=B8=9D=E6=8E=A7=E5=A7=90=E5=A6=B9=E8=8A=B1=E7=A7=92=E6=9D=80=E4=BD=A0=E6=B2=A1=E9=97=AE=E9=A2=98[26P]-=2037kxw.com=20-=20=E4=B8=AD=E5=9B=BD=E6=9C=80=E5=A4=A7=E7=9A=84=E8=89=B2=E6=83=85=E5=88=86=E4=BA=AB=E7=BD=91=E7=AB=99?= MIME-Version: 1.0
其实文件的不同不止这两处,在chrome保存的文件中图片信息可能以二进制形式的存在,而不是之前的base64的编码。新的图片内容数据如下:

ie保存的文件,图片内容如下:
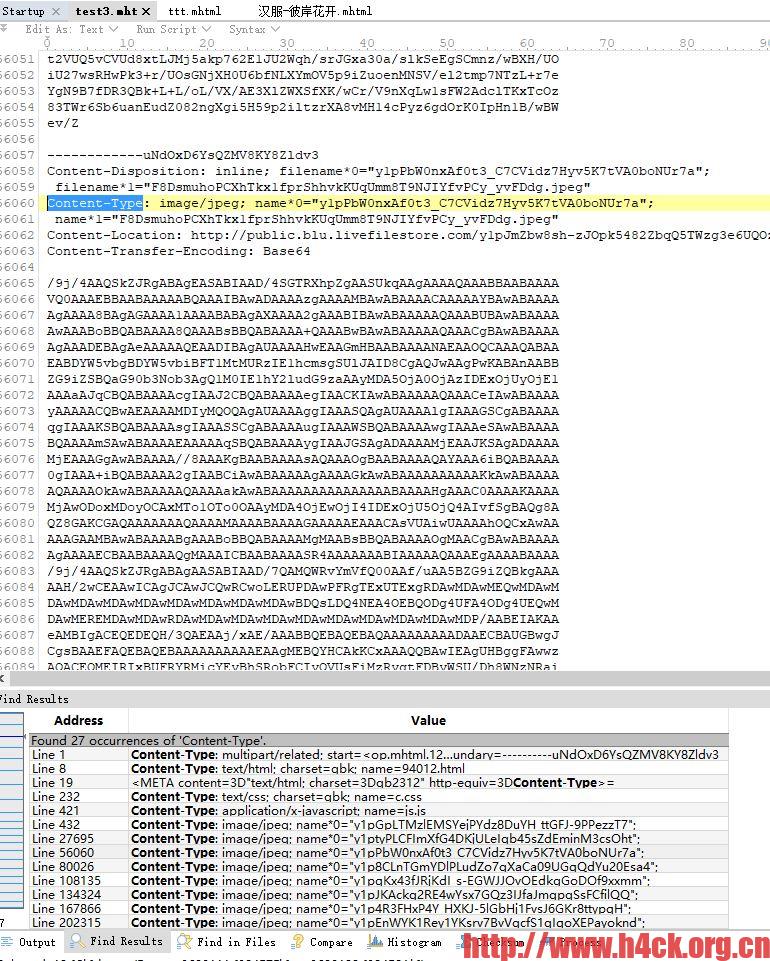
由于之前的版本并没有兼容该编码方式,因而即使找到了合适的分隔符依然无法解析图片,由于文件内容包含二进制内容所以只能切换为二进制模式读取。
于是要解决这个问题,可以采用如下的两个办法:
- 统一使用二进制模式读文件,然后定位边界线。
- 只对chrome保存的文件进行处理,我选择这种方法,主要是不用在测试第一种方法的兼容性。
关键代码如下:
# -*- coding: utf-8 -*-
"""
@author: obaby
@license: (C) Copyright 2013-2020, obaby@mars.
@contact: root@obaby.org.cn
@link: http://www.obaby.org.cn
http://www.h4ck.org.cn
http://www.findu.co
@file: baby_mht_image_extractor.py
@time: 2020/5/22 20:46
@desc:
"""
import base64
import getopt
import os
import quopri
import sys
import hashlib
from pyfiglet import Figlet
current_path = os.path.dirname(os.path.abspath(__file__))
dirname, filename = os.path.split(os.path.abspath(sys.argv[0]))
current_path = dirname
OUT_PATH = os.path.join(current_path, 'out')
def convert_mht_to_list(boundary, html_content):
return str(html_content).split(boundary)
def convert_mht_to_list_chrome(boundary, html_content):
return html_content.split(boundary)
def get_boundary(html_content):
return '--' + str(html_content).split(';')[-1].split('=')[-1]
def get_boundary_chrome(f):
for i in range(1, 30):
l = f.readline()
if 'boundary' in str(l):
l = l.replace(b'"', b'').replace(b'\r', b'').replace(b'\n', b'').replace(b'\\', b'')
bb = bytes.decode(l).split('=')
return bb[-1]
return ''
def make_dir(floder_name):
PATH = os.path.join(OUT_PATH, floder_name)
if not os.path.exists(PATH):
os.makedirs(PATH)
os.chdir(PATH)
return PATH
def save_image_file(image_content, path, file_name):
try:
file_path = os.path.join(path, file_name)
make_dir(path)
with open(file_path, 'wb') as f:
f.write(image_content)
print('[S] 保存图片成功')
return file_path
except Exception as e:
# print(e)
print('[S] 保存图片失败: ' + str(e))
return None
def get_content_type(sub_content):
content_type = 'Unknown'
for l in sub_content:
if 'Content-Type' in l:
content_type = l.split(';')[0].split(':')[1]
break
return content_type
def get_content_encoding(sub_content):
content_encoding = 'unknown'
pass_count = 0
for l in sub_content:
if 'Content-Transfer-Encoding' in l:
content_encoding = l.split(':')[1].replace(' ', '')
break
pass_count += 1
return content_encoding, pass_count
def get_content_type_and_content(line, sub_path_name, index):
line = str(line)
sub_content = line.split('\n')
if 'Content-Disposition' in line:
try:
file_name = sub_content[0].split(';')[1].split('=')[1]
if 'filename*0' in sub_content[0]:
file_name = 'default.jpg'
except:
file_name = 'default.jpg'
content_type = get_content_type(sub_content)
content_encoding, psc = get_content_encoding(sub_content)
content = ''.join(sub_content[psc + 1:])
if 'image' in content_type:
print('_'*100)
filename = str(index) + '_' + file_name
print('[S] 正在保存图片文件:', filename)
decoded_body = None
if content_encoding.lower() == 'quoted-printable':
decoded_body = quopri.decodestring(content)
if content_encoding.lower() == 'base64':
decoded_body = base64.b64decode(content)
if decoded_body:
save_image_file(decoded_body, sub_path_name, filename)
else:
print('[S] 图片解码失败,无法保存')
return
def print_usage():
print('*' * 100)
# f = Figlet(font='slant')
f = Figlet()
print(f.renderText('obaby@mars'))
print('mht image extractor by obaby')
print('Verson: 0.9.22')
print('baby_mht_image_extractor -f -o
上一篇文章地址:
https://image.h4ck.org.cn/2020/05/mht文件图片解析工具/
完整代码请参考github:
https://github.com/obaby/mht-image-extractor
1 comment
支持一下,不错!。✧* ꧁超强꧂✧*。