网上关于yolov5 gpu环境搭建的文章也是一抓一大把,但是实际上好用不好用并不清楚。所以要想按照那些所谓的教程安装配置,很可能会失败。当然按照我的文章进行安装配置也可能会失败。逼乎上有个帖子问新手学习一门语言该不该用ide,还有一大群人建议新手配置各种环境,用sb vim等编辑器,配置各种执行路径,各种源代码路径、库路径。这tm一个ide就解决的问题,非得折腾半天,这是为了让没入门的赶紧放弃?
我简单的说一下我的安装流程:
1.下载cuda安装文件,https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exe_network 安装cuda,默认一路next 即可。
2.安装pytorch-gpu,yolov5的运行环境主要依赖于pytorch。通过官网https://pytorch.org可以找到对应的安装命令:
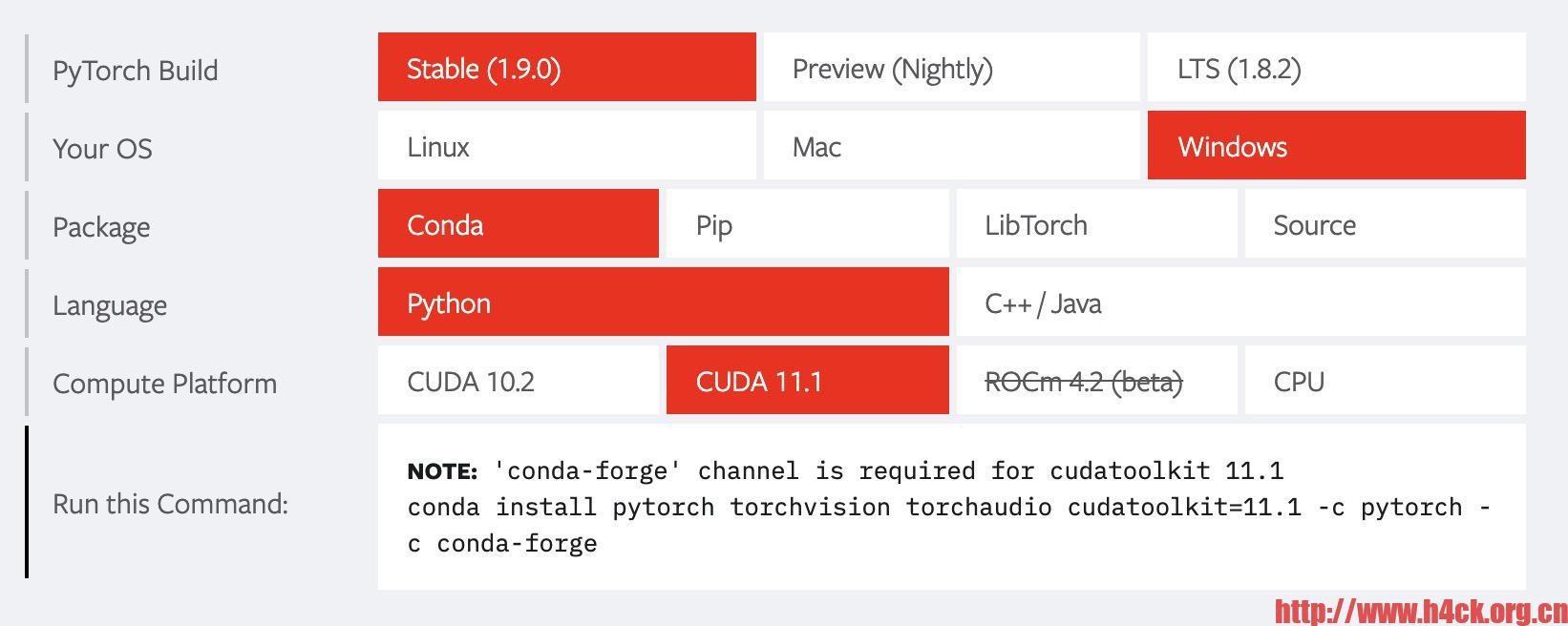
我使用的就是上面的安装命令:
NOTE: 'conda-forge' channel is required for cudatoolkit 11.1 conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c conda-forge
3.安装yolov5,一定要最后安装,前面通过conda安装了pytorch gpu版本之后,通过pip安装yolov5的依赖库就不再需要安装pytorch了。
$ git clone https://github.com/ultralytics/yolov5 $ cd yolov5 $ pip install -r requirements.txt
4.安装完成之后可以通过下面的代码进行测试:
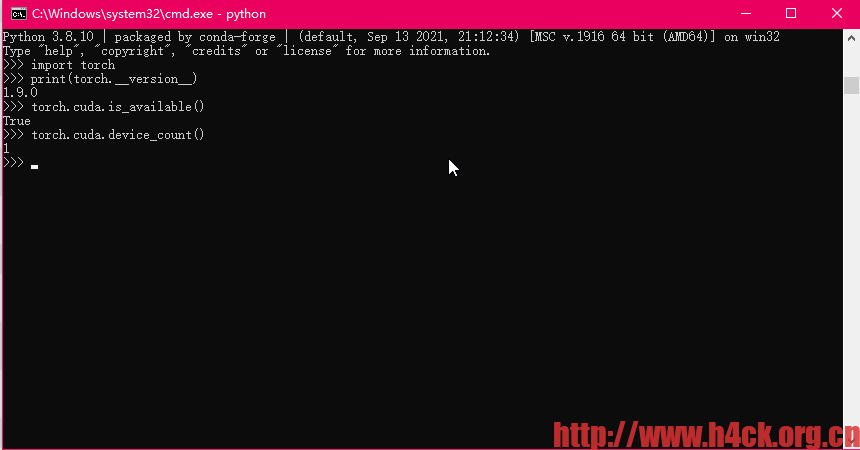
同样,我创建了一个conda环境,可以通过这个链接下载对应的conda环境:https://anaconda.org/obaby/yolov5-gpu
到这里安装就完成了,可以开始训练了。但是很不幸的是,报了下面的错误:
(E:\anaconda_dirs\venvs\yolov5-gpu) C:\Users\obaby>cd /d F:\Pycharm_Projects\yolov5 (E:\anaconda_dirs\venvs\yolov5-gpu) F:\Pycharm_Projects\yolov5>python train_ads.py train: weights=yolov5s.pt, cfg=, data=data/ads.yaml, hyp=data/hyps/hyp.scratch.yaml, epochs=300, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=True, adam=False, sync_bn=False, workers=8, project=runs/train, entity=None, name=exp, exist_ok=False, quad=False, linear_lr=False, label_smoothing=0.0, upload_dataset=False, bbox_interval=-1, save_period=-1, artifact_alias=latest, local_rank=-1, freeze=0, patience=30 github: remote: Enumerating objects: 4, done. remote: Counting objects: 100% (4/4), done. remote: Compressing objects: 100% (4/4), done. remote: Total 4 (delta 0), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (4/4), 14.05 KiB | 410.00 KiB/s, done. From https://github.com/ultralytics/yolov5 aa18599..fcb225c master -> origin/master YOLOv5 is out of date by 26 commits. Use `git pull` or `git clone https://github.com/ultralytics/yolov5` to update. YOLOv5 v5.0-405-gfad57c2 torch 1.9.0 CUDA:0 (NVIDIA GeForce RTX 3080, 10240.0MB) hyperparameters: lr0=0.01, lrf=0.2, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0 Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 runs (RECOMMENDED) TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/ Overriding model.yaml nc=80 with nc=1 from n params module arguments 0 -1 1 3520 models.common.Focus [3, 32, 3] 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] 2 -1 1 18816 models.common.C3 [64, 64, 1] 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] 4 -1 3 156928 models.common.C3 [128, 128, 3] 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] 6 -1 3 625152 models.common.C3 [256, 256, 3] 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] 8 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]] 9 -1 1 1182720 models.common.C3 [512, 512, 1, False] 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 12 [-1, 6] 1 0 models.common.Concat [1] 13 -1 1 361984 models.common.C3 [512, 256, 1, False] 14 -1 1 33024 models.common.Conv [256, 128, 1, 1] 15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 16 [-1, 4] 1 0 models.common.Concat [1] 17 -1 1 90880 models.common.C3 [256, 128, 1, False] 18 -1 1 147712 models.common.Conv [128, 128, 3, 2] 19 [-1, 14] 1 0 models.common.Concat [1] 20 -1 1 296448 models.common.C3 [256, 256, 1, False] 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] 22 [-1, 10] 1 0 models.common.Concat [1] 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] 24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]] Model Summary: 283 layers, 7063542 parameters, 7063542 gradients, 16.4 GFLOPs Transferred 356/362 items from yolov5s.pt Scaled weight_decay = 0.0005 optimizer: SGD with parameter groups 59 weight, 62 weight (no decay), 62 bias train: Scanning 'data\train.cache' images and labels... 16 found, 0 missing, 0 empty, 0 corrupted: 100%|█| 16/16 [00:00 val: Scanning 'data\val.cache' images and labels... 2 found, 0 missing, 0 empty, 0 corrupted: 100%|█| 2/2 [00:00<?, ?it Plotting labels... Traceback (most recent call last): File "<string>", line 1, in <module> File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 116, in spawn_main exitcode = _main(fd, parent_sentinel) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 125, in _main prepare(preparation_data) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 236, in prepare _fixup_main_from_path(data['init_main_from_path']) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path main_content = runpy.run_path(main_path, File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\runpy.py", line 265, in run_path return _run_module_code(code, init_globals, run_name, File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\runpy.py", line 97, in _run_module_code _run_code(code, mod_globals, init_globals, File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\runpy.py", line 87, in _run_code exec(code, run_globals) File "F:\Pycharm_Projects\yolov5\train_ads.py", line 20, in <module> import torch File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\__init__.py", line 124, in <module> raise err OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\lib\cudnn_adv_infer64_8.dll" or one of its dependencies. Traceback (most recent call last): File "<string>", line 1, in <module> File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 116, in spawn_main exitcode = _main(fd, parent_sentinel) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 125, in _main prepare(preparation_data) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 236, in prepare _fixup_main_from_path(data['init_main_from_path']) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path main_content = runpy.run_path(main_path, File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\runpy.py", line 265, in run_path return _run_module_code(code, init_globals, run_name, File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\runpy.py", line 97, in _run_module_code _run_code(code, mod_globals, init_globals, File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\runpy.py", line 87, in _run_code exec(code, run_globals) File "F:\Pycharm_Projects\yolov5\train_ads.py", line 20, in <module> import torch File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\__init__.py", line 124, in <module> raise err OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\lib\cudnn_adv_infer64_8.dll" or one of its dependencies. autoanchor: Analyzing anchors... anchors/target = 4.44, Best Possible Recall (BPR) = 1.0000 Image sizes 640 train, 640 val Using 8 dataloader workers Logging results to runs\train\exp16 Starting training for 300 epochs... Epoch gpu_mem box obj cls labels img_size 0%| | 0/1 [00:00<?, ?it/s] Traceback (most recent call last): File "train_ads.py", line 610, in <module> main(opt) File "train_ads.py", line 508, in main train(opt.hyp, opt, device) File "train_ads.py", line 286, in train for i, (imgs, targets, paths, _) in pbar: # batch ------------------------------------------------------------- File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\tqdm\std.py", line 1185, in __iter__ for obj in iterable: File "F:\Pycharm_Projects\yolov5\utils\datasets.py", line 139, in __iter__ yield next(self.iterator) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\utils\data\dataloader.py", line 521, in __next__ data = self._next_data() File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\utils\data\dataloader.py", line 1203, in _next_data return self._process_data(data) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\utils\data\dataloader.py", line 1229, in _process_data data.reraise() File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\_utils.py", line 425, in reraise raise self.exc_type(msg) cv2.error: Caught error in DataLoader worker process 0. Original Traceback (most recent call last): File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\utils\data\_utils\worker.py", line 287, in _worker_loop data = fetcher.fetch(index) File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\utils\data\_utils\fetch.py", line 44, in fetch data = [self.dataset[idx] for idx in possibly_batched_index] File "E:\anaconda_dirs\venvs\yolov5-gpu\lib\site-packages\torch\utils\data\_utils\fetch.py", line 44, in <listcomp> data = [self.dataset[idx] for idx in possibly_batched_index] File "F:\Pycharm_Projects\yolov5\utils\datasets.py", line 536, in __getitem__ img, labels = load_mosaic(self, index) File "F:\Pycharm_Projects\yolov5\utils\datasets.py", line 666, in load_mosaic img, _, (h, w) = load_image(self, index) File "F:\Pycharm_Projects\yolov5\utils\datasets.py", line 645, in load_image im = cv2.imread(path) # BGR cv2.error: OpenCV(4.5.3) C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-q3d_8t8e\opencv\modules\core\src\alloc.cpp:73: error: (-4:Insufficient memory) Failed to allocate 7581600 bytes in function 'cv::OutOfMemoryError'
到晚上搜一下这个错误:OSError: [WinError 1455] 页面文件太小,无法完成操作,会发现多数的文章会告诉大家去修改虚拟内存,修改虚拟内存之后:
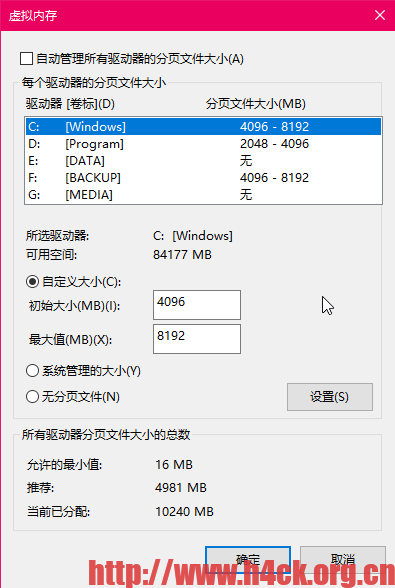
发现tm没什么鸟用啊。依然报错,网上的另外一个解决方案是修改为”自动管理所有驱动器的分页文件大小”,这个方法我没试,所以不知道有没有用。不过搜索之后还发现另外一个方法就是修改num_workers为0,不知道依据是什么(https://blog.csdn.net/weixin_43817670/article/details/116748349)。
刚看到这个方法不以为然,我觉得32g的内存,不至于这么挫把。worker数量多了就挂了?
不过事实证明,修改worker数量确实是管用的。不过这个系统报错tm有点扯淡,貌似也不是虚拟内存的问题??
def parse_opt(known=False):
###
parser.add_argument('--workers', type=int, default=4, help='maximum number of dataloader workers')
修改上面的参数之后就可以正常运行了,这tm神坑啊。
硬件配置信息:
Processor (CPU) CPU Name Intel® Core™ i9-10900K CPU @ 3.70GHz Threading 1 CPU - 10 Core - 20 Threads Frequency 4898.82 MHz (49 * 99.98 MHz) - Uncore: 4299 MHz Multiplier Current: 49 / Min: 8 / Max: 53 Architecture Comet Lake / Stepping: Q0/G1 / Technology: 14 nm CPUID / Ext. 6.5.5 / 6.A5 IA Extensions MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, EM64T, VT-x, AES, AVX, AVX2, FMA3 Caches L1D : 32 KB / L2 : 256 KB / L3 : 20480 KB Caches Assoc. L1D : 8-way / L2 : 4-way / L3 : 16-way Microcode Rev. 0xCA TDP / Vcore 125 Watts / 1.226 Volts Temperature 61 °C / 142 °F Type Retail (Stock Frequency : 3700 MHz) Cores Frequencies #00: 4898.82 MHz #01: 4898.82 MHz #02: 4898.82 MHz #03: 4898.82 MHz #04: 4898.82 MHz #05: 4898.82 MHz #06: 4898.82 MHz #07: 4898.82 MHz #08: 4898.82 MHz #09: 4898.82 MHz Motherboard Model MSI MPG Z490 GAMING CARBON WIFI (MS-7C73) Socket Socket 1200 LGA North Bridge Intel Comet Lake rev 05 South Bridge Intel Z490 rev 00 BIOS American Megatrends Inc. 1.20 (05/21/2020) Memory (RAM) Total Size 32768 MB Type Dual Channel (128 bit) DDR4-SDRAM Frequency 1333.1 MHz (DDR4-2666) - Ratio 1:20 Timings 19-19-19-43-2 (tCAS-tRCD-tRP-tRAS-tCR) Slot #1 Module A-Data Technology 16384 MB (DDR4-2662) - XMP 2.0 - P/N: DDR4 3600 Slot #2 Module A-Data Technology 16384 MB (DDR4-2662) - XMP 2.0 - P/N: DDR4 3600 Graphic Card (GPU) GPU Type NVIDIA GeForce RTX 3080 (GA102-200) @ 210 MHz GPU Brand Micro-Star International Co. Lt GPU Specs GA102-200 / Process: 8nm / Transistors: 28.3B / Die Size: 628 mm² / TDP: 320W GPU Units Shader Units: 8704 / Texture Units (TMU): 272 / Render Units (ROP): 96 GPU VRAM 10240 MB GDDR6X / 320-bit Bus @ 405 MHz (Micron) GPU APIs DirectX 12.0 (12_2) / OpenGL 4.6 / OpenCL 1.2 / Vulkan 1.2