
xiurenji.exe 可执行文件名称 帮助: -h 显示帮助说明 必选参数: -a 整站爬取 -q 搜索爬取,针对关键字搜索之后对于搜索结果页进行爬取 可选参数: -p 指定下载目录,默认下载路径为当前exe所在目录下的images文件夹 -s 指定服务器地址,例如:http://www.xiurenji.vip url不要带最后的/
更新日志:
增加-s 参数支持: -s 指定服务器地址,例如:http://www.xiurenji.vip url不要带最后的/
黑客程序媛 / 逆向工程师 / 人工智能学徒 / 用爱发电的独立开发者
xiurenji.exe 可执行文件名称 帮助: -h 显示帮助说明 必选参数: -a 整站爬取 -q 搜索爬取,针对关键字搜索之后对于搜索结果页进行爬取 可选参数: -p 指定下载目录,默认下载路径为当前exe所在目录下的images文件夹 -s 指定服务器地址,例如:http://www.xiurenji.vip url不要带最后的/
更新日志:
增加-s 参数支持: -s 指定服务器地址,例如:http://www.xiurenji.vip url不要带最后的/

功能:支持全站爬取,搜索爬取。想下载什么内容自己定制,目前版本不支持独立页面下载,后续可能会考虑支持,目前我的目标是为了爬取整个网站,所以单页面下载功能不一定会做,即使做了也不一定什么时候会上。 参数说明:
xiurenji.exe 可执行文件名称 帮助: -h 显示帮助说明 必选参数: -a 整站爬取 -q 搜索爬取,针对关键字搜索之后对于搜索结果页进行爬取 可选参数: -p 制定下载目录,默认下载路径为当前exe所在目录下的images文件夹
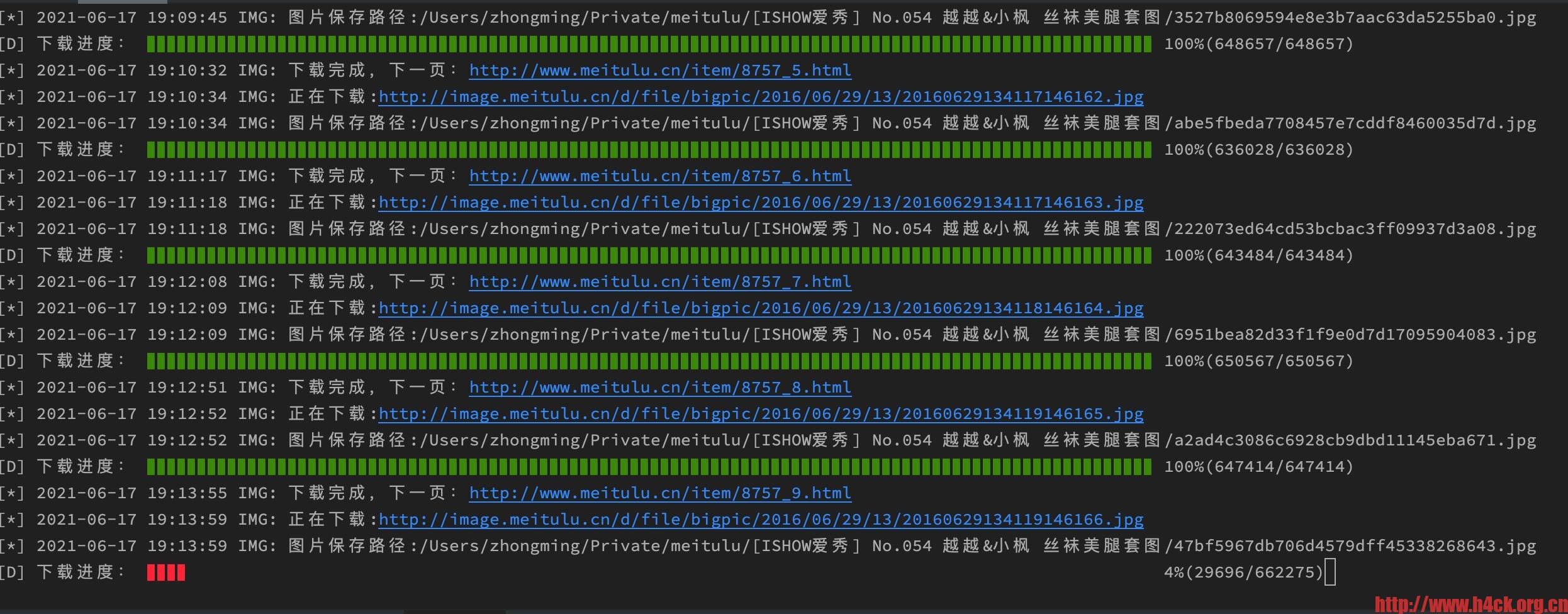
代码:
def proxy_get_content_stream(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
return requests.get(url, headers=HEADERS, stream=True, timeout=300)
def save_image_from_url_with_progress(url, cnt):
with closing(proxy_get_content_stream(url)) as response:
chunk_size = 1024 # 单次请求最大值
content_size = int(response.headers['content-length']) # 内容体总大小
data_count = 0
with open(cnt, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
data_count = data_count + len(data)
now_position = (data_count / content_size) * 100
print("\r[D] 下载进度: %s %d%%(%d/%d)" % (int(now_position) * '▊' + (100 - int(now_position)) * ' ',
now_position,
data_count,
content_size,), end=" ")
print('')

****************************************************************************************************
_ _ ____
___ | |__ __ _| |__ _ _ / __ \ _ __ ___ __ _ _ __ ___
/ _ \| '_ \ / _` | '_ \| | | |/ / _` | '_ ` _ \ / _` | '__/ __|
| (_) | |_) | (_| | |_) | |_| | | (_| | | | | | | (_| | | \__ \
\___/|_.__/ \__,_|_.__/ \__, |\ \__,_|_| |_| |_|\__,_|_| |___/
|___/ \____/
美图录爬虫
Verson: 21.6.15
Blog: http://www.h4ck.org.cn
****************************************************************************************************
****************************************************************************************************
[*] 2021-06-16 21:00:11 CAT: 开始分析分类信息......
[*] 2021-06-16 21:00:11 泳装: http://www.meitulu.cn/t/yongzhuang/
[*] 2021-06-16 21:00:11 可爱: http://www.meitulu.cn/t/keai/
[*] 2021-06-16 21:00:11 日本美女: http://www.meitulu.cn/t/ribenmeinv/
BeautifulSoup4解析页面的时候发现有一部分内容是乱码,刚开始还以为是pycharm的问题,后来发现可能问题不是出在pycharm上,因为普通的print打印的中文是没有问题的。测试代码如下:
def proxy_get(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
req = requests.get(url, headers=HEADERS)
return req.text
def get_sub_pages_test(url):
'''
http://www.meitulu.cn/t/shishen/
:param url:
:return:
'''
bs = BeautifulSoup(proxy_get(url), "html.parser")
boxes = bs.find('div', class_='boxs')
lis = boxes.find_all('li')
log_text('PAGE', '开始分析页面链接', is_begin=True)
for l in lis:
p = l.find('p', class_='p_title')
print( p.text)
