网上关于yolov5 gpu环境搭建的文章也是一抓一大把,但是实际上好用不好用并不清楚。所以要想按照那些所谓的教程安装配置,很可能会失败。当然按照我的文章进行安装配置也可能会失败。逼乎上有个帖子问新手学习一门语言该不该用ide,还有一大群人建议新手配置各种环境,用sb vim等编辑器,配置各种执行路径,各种源代码路径、库路径。这tm一个ide就解决的问题,非得折腾半天,这是为了让没入门的赶紧放弃?
我简单的说一下我的安装流程:
1.下载cuda安装文件,https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exe_network 安装cuda,默认一路next 即可。
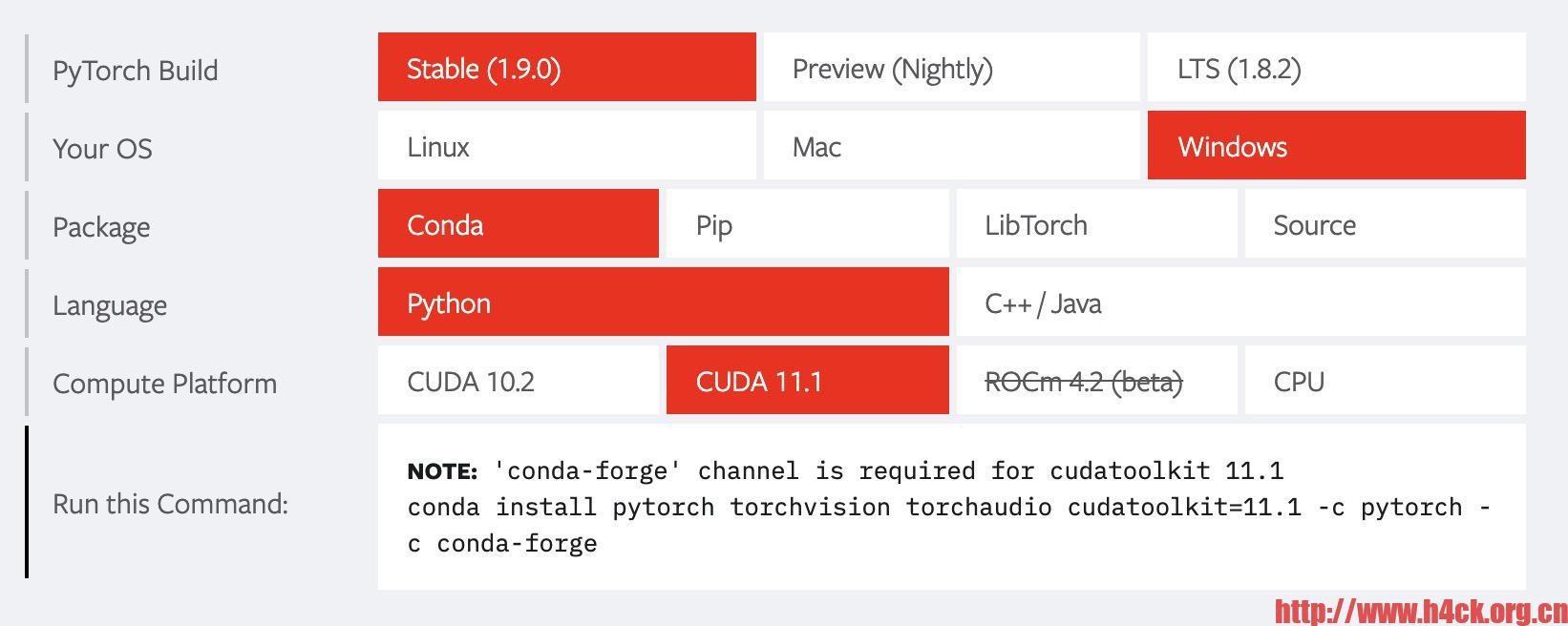
2.安装pytorch-gpu,yolov5的运行环境主要依赖于pytorch。通过官网https://pytorch.org可以找到对应的安装命令: