
HTTrack is a free (GPL, libre/free software) and easy-to-use offline browser utility.
It allows you to download a World Wide Web site from the Internet to a local directory, building recursively all directories, getting HTML, images, and other files from the server to your computer. HTTrack arranges the original site’s relative link-structure. Simply open a page of the “mirrored” website in your browser, and you can browse the site from link to link, as if you were viewing it online. HTTrack can also update an existing mirrored site, and resume interrupted downloads. HTTrack is fully configurable, and has an integrated help system.
WinHTTrack is the Windows (from Windows 2000 to Windows 10 and above) release of HTTrack, and WebHTTrack the Linux/Unix/BSD release. See the download page.
命令行参数:
httrack "http://www.qdxiangshidianqi.com" -O "xsdq" "+*.qdxiangshidianqi.com/*" -v
下载效果:
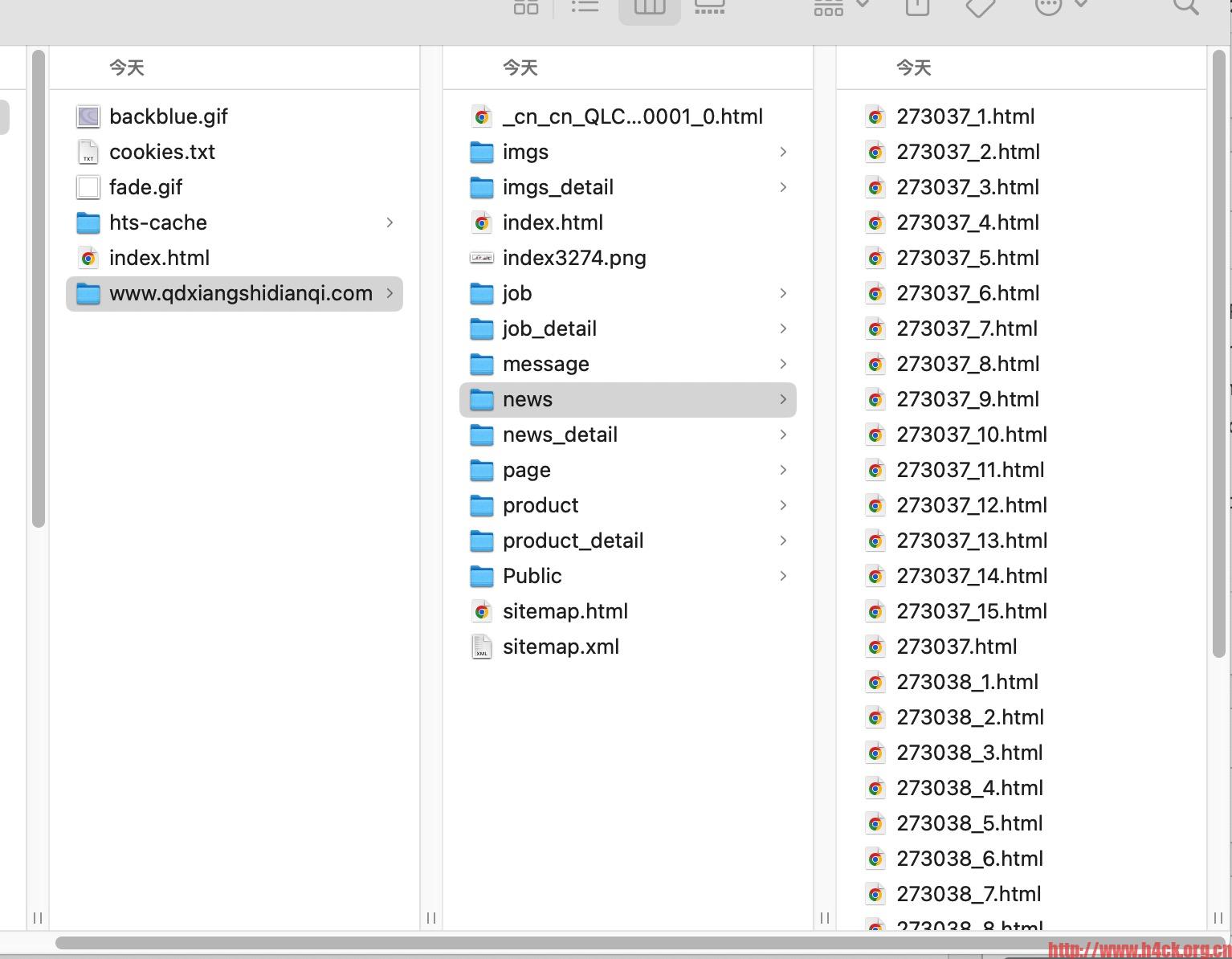
参数说明:
httrack --help
Unfortunately, while this outputs a though list of options, it is somewhat less helpful it might be for those who don't know what the options all mean and haven't used them before. On the other hand, this is most useful for those who already know how to use the program but don't remember some obscure option that they haven't used for some time.
The rest of this manual is dedicated to detailing what you find in the help message and providing examples - lots and lots of examples... Here is what you get (page by page - use to move to the next page in the real program) if you type 'httrack --help':
>httrack --help
HTTrack version 3.03BETAo4 (compiled Jul 1 2001)
usage: ./httrack ] [-]
with options listed below: (* is the default value)
General options:
O path for mirror/logfiles+cache (-O path_mirror[,path_cache_and_logfiles]) (--path )
%O top path if no path defined (-O path_mirror[,path_cache_and_logfiles])
Action options:
w *mirror web sites (--mirror)
W mirror web sites, semi-automatic (asks questions) (--mirror-wizard)
g just get files (saved in the current directory) (--get-files)
i continue an interrupted mirror using the cache
Y mirror ALL links located in the first level pages (mirror links) (--mirrorlinks)
Proxy options:
P proxy use (-P proxy:port or -P user:pass@proxy:port) (--proxy )
%f *use proxy for ftp (f0 don't use) (--httpproxy-ftp[=N])
Limits options:
rN set the mirror depth to N (* r9999) (--depth[=N])
%eN set the external links depth to N (* %e0) (--ext-depth[=N])
mN maximum file length for a non-html file (--max-files[=N])
mN,N' for non html (N) and html (N')
MN maximum overall size that can be uploaded/scanned (--max-size[=N])
EN maximum mirror time in seconds (60=1 minute, 3600=1 hour) (--max-time[=N])
AN maximum transfer rate in bytes/seconds (1000=1kb/s max) (--max-rate[=N])
%cN maximum number of connections/seconds (*%c10)
GN pause transfer if N bytes reached, and wait until lock file is deleted (--max-pause[=N])
Flow control:
cN number of multiple connections (*c8) (--sockets[=N])
TN timeout, number of seconds after a non-responding link is shutdown (--timeout)
RN number of retries, in case of timeout or non-fatal errors (*R1) (--retries[=N])
JN traffic jam control, minimum transfert rate (bytes/seconds) tolerated for a link (--min-rate[=N])
HN host is abandonned if: 0=never, 1=timeout, 2=slow, 3=timeout or slow (--host-control[=N])
Links options:
%P *extended parsing, attempt to parse all links, even in unknown tags or Javascript (%P0 don't use) (--extended-parsing[=N])
n get non-html files 'near' an html file (ex: an image located outside) (--near)
t test all URLs (even forbidden ones) (--test)
%L )
Build options:
NN structure type (0 *original structure, 1+: see below) (--structure[=N])
or user defined structure (-N "%h%p/%n%q.%t")
LN long names (L1 *long names / L0 8-3 conversion) (--long-names[=N])
KN keep original links (e.g. http://www.adr/link) (K0 *relative link, K absolute links, K3 absolute URI links) (--keep-links[=N])
x replace external html links by error pages (--replace-external)
%x do not include any password for external password protected websites (%x0 include) (--no-passwords)
%q *include query string for local files (useless, for information purpose only) (%q0 don't include) (--include-query-string)
o *generate output html file in case of error (404..) (o0 don't generate) (--generate-errors)
X *purge old files after update (X0 keep delete) (--purge-old[=N])
Spider options:
bN accept cookies in cookies.txt (0=do not accept,* 1=accept) (--cookies[=N])
u check document type if unknown (cgi,asp..) (u0 don't check, * u1 check but /, u2 check always) (--check-type[=N])
j *parse Java Classes (j0 don't parse) (--parse-java[=N])
sN follow robots.txt and meta robots tags (0=never,1=sometimes,* 2=always) (--robots[=N])
%h force HTTP/1.0 requests (reduce update features, only for old servers or proxies) (--http-10)
%B tolerant requests (accept bogus responses on some servers, but not standard!) (--tolerant)
%s update hacks: various hacks to limit re-transfers when updating (identical size, bogus response..) (--updatehack)
%A assume that a type (cgi,asp..) is always linked with a mime type (-%A php3=text/html) (--assume )
Browser ID:
F user-agent field (-F "user-agent name") (--user-agent )
%F footer string in Html code (-%F "Mirrored [from host %s [file %s [at %s]]]" (--footer )
%l preffered language (-%l "fr, en, jp, *" (--language )
Log, index, cache
C create/use a cache for updates and retries (C0 no cache,C1 cache is prioritary,* C2 test update before) (--cache[=N])
k store all files in cache (not useful if files on disk) (--store-all-in-cache)
%n do not re-download locally erased files (--do-not-recatch)
%v display on screen filenames downloaded (in realtime) (--display)
Q no log - quiet mode (--do-not-log)
q no questions - quiet mode (--quiet)
z log - extra infos (--extra-log)
Z log - debug (--debug-log)
v log on screen (--verbose)
f *log in files (--file-log)
f2 one single log file (--single-log)
I *make an index (I0 don't make) (--index)
%I make an searchable index for this mirror (* %I0 don't make) (--search-index)
Expert options:
pN priority mode: (* p3) (--priority[=N])
0 just scan, don't save anything (for checking links)
1 save only html files
2 save only non html files
*3 save all files
7 get html files before, then treat other files
S stay on the same directory
D *can only go down into subdirs
U can only go to upper directories
B can both go up&down into the directory structure
a *stay on the same address
d stay on the same principal domain
l stay on the same TLD (eg: .com)
e go everywhere on the web
%H debug HTTP headers in logfile (--debug-headers)
Guru options: (do NOT use)
#0 Filter test (-#0 '*.gif' 'www.bar.com/foo.gif')
#f Always flush log files
#FN Maximum number of filters
#h Version info
#K Scan stdin (debug)
#L Maximum number of links (-#L1000000)
#p Display ugly progress information
#P Catch URL
#R Old FTP routines (debug)
#T Generate transfer ops. log every minutes
#u Wait time
#Z Generate transfer rate statictics every minutes
#! Execute a shell command (-#! "echo hello")
Command-line specific options:
V execute system command after each files ($0 is the filename: -V "rm \$0") (--userdef-cmd )
%U run the engine with another id when called as root (-%U smith) (--user )
Details: Option N
N0 Site-structure (default)
N1 HTML in web/, images/other files in web/images/
N2 HTML in web/HTML, images/other in web/images
N3 HTML in web/, images/other in web/
N4 HTML in web/, images/other in web/xxx, where xxx is the file extension
(all gif will be placed onto web/gif, for example)
N5 Images/other in web/xxx and HTML in web/HTML
N99 All files in web/, with random names (gadget !)
N100 Site-structure, without www.domain.xxx/
N101 Identical to N1 exept that "web" is replaced by the site's name
N102 Identical to N2 exept that "web" is replaced by the site's name
N103 Identical to N3 exept that "web" is replaced by the site's name
N104 Identical to N4 exept that "web" is replaced by the site's name
N105 Identical to N5 exept that "web" is replaced by the site's name
N199 Identical to N99 exept that "web" is replaced by the site's name
N1001 Identical to N1 exept that there is no "web" directory
N1002 Identical to N2 exept that there is no "web" directory
N1003 Identical to N3 exept that there is no "web" directory (option set for g option)
N1004 Identical to N4 exept that there is no "web" directory
N1005 Identical to N5 exept that there is no "web" directory
N1099 Identical to N99 exept that there is no "web" directory
Details: User-defined option N
%n Name of file without file type (ex: image) (--do-not-recatch)
%N Name of file, including file type (ex: image.gif)
%t File type (ex: gif)
%p Path [without ending /] (ex: /someimages)
%h Host name (ex: www.someweb.com) (--http-10)
%M URL MD5 (128 bits, 32 ascii bytes)
%Q query string MD5 (128 bits, 32 ascii bytes)
%q small query string MD5 (16 bits, 4 ascii bytes) (--include-query-string)
%s? Short name version (ex: %sN)
%[param] param variable in query string
网站:
12 comments
不时有类似需求,先存下
不明觉厉,我在想,如果某社区重启了,是不是可以用这个工具备份数据?
如果是静态页面应该问题不大,如果是动态生成的页面可能就有些麻烦。
我闲着没事把杜老师说下了一遍!
这……好闲
下载后的页面链接都是正确的吗
当然。为什么会觉得不正确呢?
我记得之前有个浏览器插件也可以,当然,效果也是一样的。
我之前用webzip,然后单个网页用网页扒手,原来仿照就是下载这个单页,然后前端用人家,直接套cms到这个前端里面。大哥你又要下载丝袜网站页面吗。
并不是,之前做的一个静态web项目没有源代码了。直接把页面重新备份一下。
换显卡啦!
这么迅速~~~恭喜啊,这不得直接飞起了。